使用 scrapy 爬取豆瓣电影 Top250
最近在学习使用 python 做数据分析,正好今天学了下 scrapy ,来写个爬虫练练手吧。因为是第一次写爬虫,先来个简单点的,那就爬豆瓣电影 Top250 吧。

最近在学习使用 python 做数据分析,正好今天学了下 scrapy ,来写个爬虫练练手吧。因为是第一次写爬虫,先来个简单点的,那就爬豆瓣电影 Top250 吧。
因为这次我是在 windows 上写的,之前由于 window 的开发环境配置实在是不省心,各种问题搞得很烦躁。最近试了下 Anconda 这个 python 的科学计算环境发行包,它集成了很多常用的科学计算 package,省去了很多配置环境变量的步骤,能做到开箱即用。而且自带了非常简单易用的虚拟环境,python 版本之间可以随意切换,互不干扰。
环境配置
首先使用 conda 新建一个环境(基于 python3):
conda create -n spider python=3
激活 spider 这个环境:
activate spider
接着安装相关依赖:
pip install scrapy beautifulsoup peewee
- scrapy 是我们写爬虫需要用到的框架;
- beautifulsoup 是解析 html 用到的框架;
- peewee 是一款数据库 ORM 库,可以很方便的帮你把对象和数据库表进行映射,从而让你不用写一句 SQL 就能操作数据库,我们爬到的数据需要写到 mysql 数据库中。
然后使用 scrapy 创建爬虫项目:
scrapy startproject douban
定制爬虫
首先我们先建一个 MySQL数据库 douban,设置好用户名和密码。
接着我们需要定义一个想要爬取的数据 Item,它继承了 scrapy.Item 这个类,包含了 name(电影名称)、url(详情链接)、score(电影评分)这三个数据。为了能将这些数据写入到 MySQL 数据库,我们还使用 peewee 定义了一个 Movie 类,继承于 Model 类(该类属于 peewee),并定义了相关的属性。
import scrapy
from peewee import *
db = MySQLDatabase("douban", host='localhost', user="root", passwd="123456", charset="utf8")
class DoubanMovieItem(scrapy.Item):
name = scrapy.Field()
url = scrapy.Field()
score = scrapy.Field()
class Movie(Model):
id = PrimaryKeyField()
name = CharField(verbose_name="电影名称", max_length=50, null=False, unique=False)
url = CharField(verbose_name="详情链接", null=False)
score = FloatField(verbose_name="评分", null=False, unique=False)
class Meta:
database = db
数据 Model 定义好了之后,我们需要在 spiders 这个目录下自定义一个 spider,这个 spider 需要继承 Spider 这个类。在该类中,我们需要设置 spider 的 name,以及 header(添加 header 能够模拟正常的请求,不加 header 很容易造成请求失败),在 start_requests 方法中定义开始的 url,并返回这个请求。
在 parse 这个方法中,我们使用 BeautifulSoup 来解析获取到的 response 对象,具体参数需要去豆瓣电影的 html 源码中去找。
import scrapy
from scrapy import Spider
from spider.items import DoubanMovieItem
from bs4 import BeautifulSoup
class DoubanTopMovieSpider(Spider):
name = 'DoubanTopMovie'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield scrapy.Request(url, headers=self.headers)
def parse(self, response):
item = DoubanMovieItem()
soup = BeautifulSoup(response.text, 'lxml')
movies = soup.findAll('div', {"class": 'item'})
for movie in movies:
item['name'] = movie.find('span', {'class': 'title'}).get_text()
item['url'] = movie.find('a')['href']
item['score'] = movie.find('span', {'class': 'rating_num'}).get_text()
yield item
next_url = soup.find('span', {'class': 'next'}).find('a')['href']
if next_url:
url = 'https://movie.douban.com/top250' + next_url
yield scrapy.Request(url, headers=self.headers)
末尾,我们需要获取 next_url,继续进行下一页的爬取操作。
存储到 MySQL
爬到数据之后,我们需要在 pipelines 这个 module 中将数据保存到数据库,因为我们使用的是 orm,可以看到我们没有写任何 SQL 语句,就能很方便的把数据写到数据库中。
from spider.items import Movie
class SpiderPipeline(object):
def process_item(self, item, spider):
if Movie.table_exists() == False:
Movie.create_table()
mv = Movie(name=item['name'], url=item['url'], score=item['score'])
mv.save()
return item
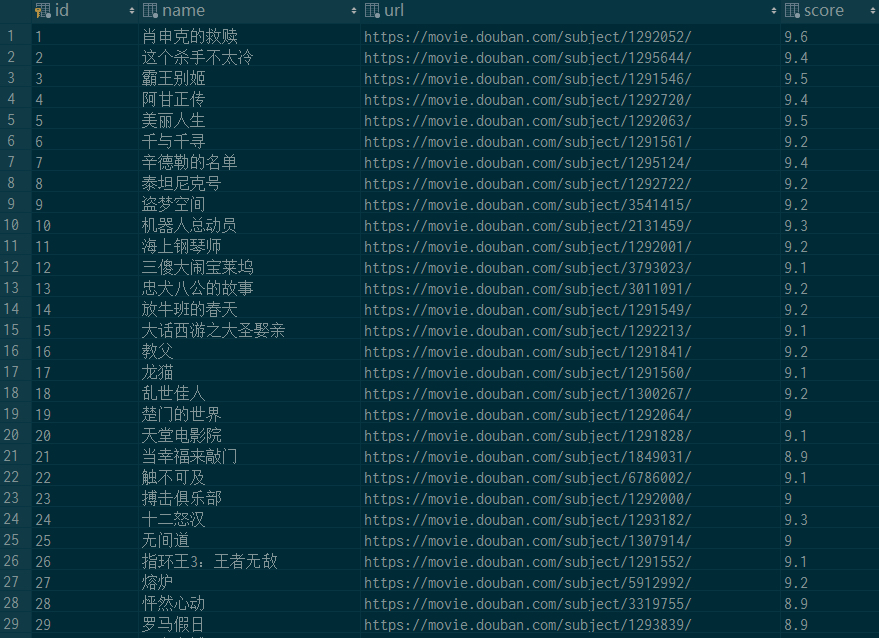
最后上一张爬取到的数据截图: