Python 爬虫辅助利器 - Selenium
需要根据一些公司名称查询相关的信息,最开始调研了一些各大数据服务商的 API,价格从 0.2 ~ 1.0元/次 不等,长期来看很不划算,而且有些 API 没有按次计费的,起步就要 1w 块,对于初创团队来说实在负担不起。

背景:需要根据一些公司名称查询相关的信息,最开始调研了一些各大数据服务商的 API,价格从 0.2 ~ 1.0元/次 不等,长期来看很不划算,而且有些 API 没有按次计费的,起步就要 1w 块,对于初创团队来说实在负担不起。
后来 Google 找到了 Selenium 这个利器,Selenium 本来是一款 UI 自动化测试的工具,但是也可以用来作为爬虫的辅助工具,可以模拟人的真实操作,比较适合常规爬虫实现起来比较复杂的场景,当然如果网站有验证码(目前很多网站都采用类似极验的方案了)也没什么好办法。以我爬取的天眼查为例,首先需要登录(不然无法查询到详细信息),然后在搜索结果页选择一条,点击进入详情页,最后在详情页中寻找需要的信息。
比较复杂的是登录这块了,如果采用常规的爬虫方案的话,需要用 Chrome 去调试登录接口请求,拼接参数,花费的时间比较多。而使用 Selenium 就完全不用关心这一步。Selenium 提供了 Chrome 插件,可以使用这个插件将登录的操作录制下来。
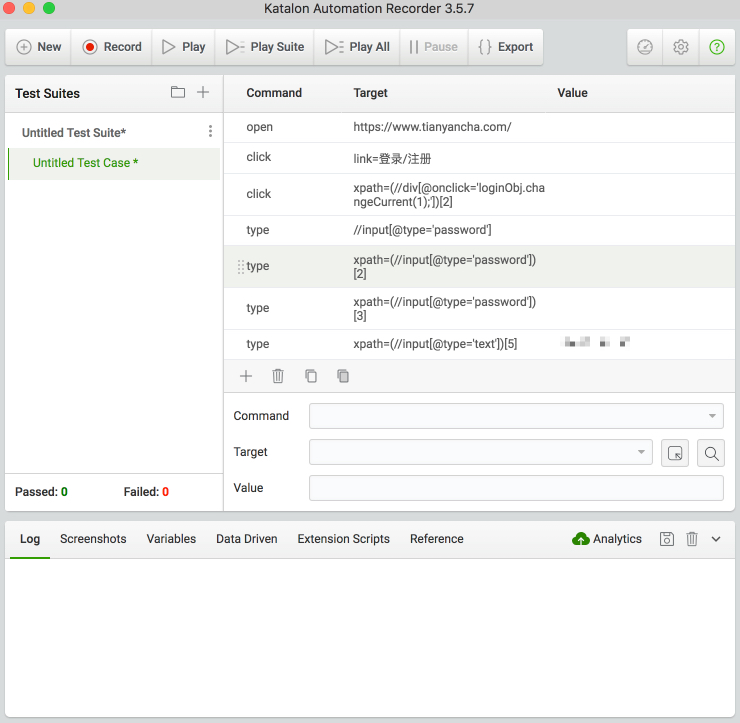
然后直接导出 Python 代码,几乎不用修改就能直接运行了。
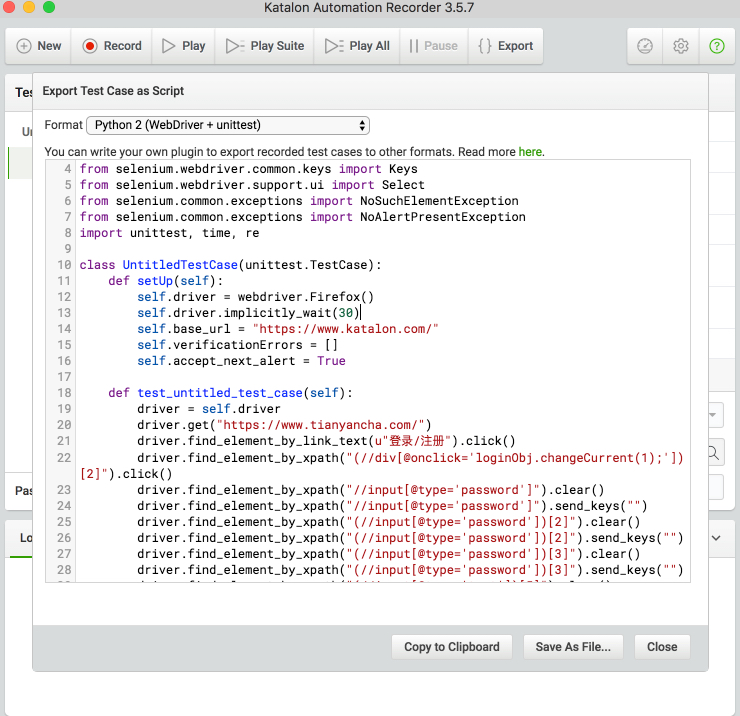
Selenium 提供丰富的 API 供你从网页中获取需要的信息,你也可以结合你用的比较顺手的工具,比如 BeautifulSoup 来实现自己的功能。
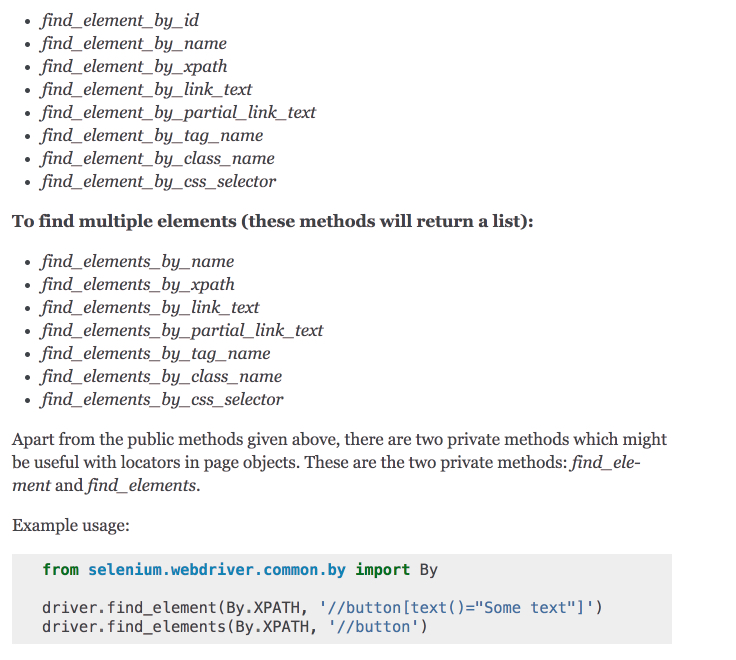
如果爬取的过程中遇到了验证码,短时间破解不了的话,你可以检测下网页的元素,Logging 一个 Error 出来,如果你用的是 Mac,还可以设置个提醒:
from subprocess import call
cmd = 'display notification \"' + \
"Notificaton memo" + '\" with title \"Titile\"'
call(["osascript", "-e", cmd])
总之,网站如果比较复杂,爬取的量也不大,对时间要求不高,可以采用这种方式,非常省时省力!如果你有更好的方式,欢迎与我交流!