从数据爬取到清洗 - 全国学校数据
由于工作原因,经常需要收集一些学校信息,全国各地的学校从幼儿园到大学都可能需要,最好的办法当然是从教育部的网站去找,结果可靠权威,也不用后续加工处理,但是教育部网站能查到的只有高校的数据,而且只有一些很基础的信息,缺少地址、邮编、网站、邮箱、联系电话等信息。此外,小学、中学也没有找到。所以就只能自己去写爬虫收集了。

由于工作原因,经常需要收集一些学校信息,全国各地的学校从幼儿园到大学都可能需要,最好的办法当然是从教育部的网站去找,结果可靠权威,也不用后续加工处理,但是教育部网站能查到的只有高校的数据,而且只有一些很基础的信息,缺少地址、邮编、网站、邮箱、联系电话等信息。此外,小学、中学也没有找到。所以就只能自己去写爬虫收集了。

爬虫
包含全国学校信息的网站有很多,而且大多信息都比较全面,另外技术上也没有验证码之类的反爬手段,使用爬虫也比较容易。选中了一家网站,看了下全国数据大约有 275000 条左右,搜索了下我的学校,从小学到大学都能找到,说明还是比较全面的。搜的时候还看到一家 网站 卖全国学校数据的,标价 3500 块。🤣
爬虫主要分为四个步骤:
- 从一个初始链接开始爬取,不断获取下一个页面的链接。
- 在每个页面中解析当前页面的学校列表,获得所有学校的详情页面链接。
- 请求详情页面链接,解析详情页面的学校信息,将结果保存到 MySQL。
- 不断重复步骤一,直至完成。
爬虫框架使用 Python 中的 Scrapy,数据解析使用 BeautifulSoup。
爬虫写好之后,开始是在本地跑,爬了一段时间看需要的时间也不短,所以就放到了 Vultr 上跑,大约每小时能爬取 4 万条数据,我是晚上睡觉前开始爬的,第二天早上起来就爬完了。
爬虫相关代码可以在 Github 上找到。
数据清洗
全国学校信息,一共爬到了 27.5 万条左右的数据,数据库大小为 175M,包含了 15 个字段(学校名称、所在地区、专业类别、学校等级、主管部门、详细地址、电话、邮编、网站、邮箱、是否为教育部直属、211、985、独立学院、学校简介等等。
数据问题
学校信息的字段比较多,而且差异比较大,比如是否是 985、211 这些只有高校才会有的属性,小学初中根本就没有。很多学校并没有网站,有的是空值,有的只是一个教育信息网站的学校介绍链接,有的还充斥这一些广告信息。我还注意到邮编信息很多学校都没有,而这个如果需要人工修复的话非常耗时费力。
针对所有字段,可以先按长度降序或者升序排列,查看是否有异常值,比如下面这些字段就有很多问题:

学校名称中包含了广告,其他名称也存在部分广告信息。
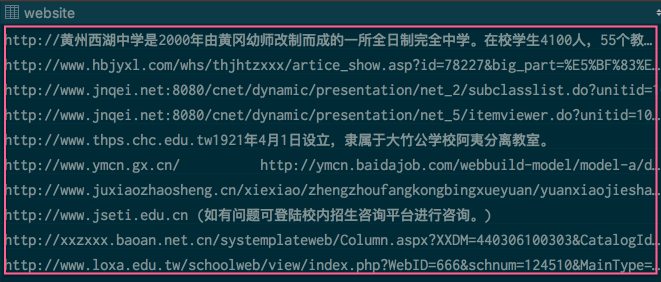
网站地址格式错误。
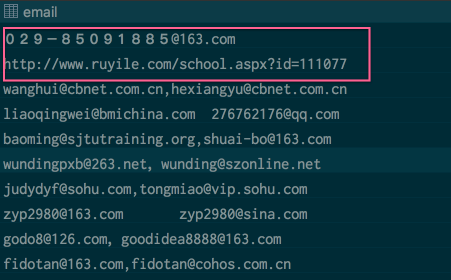
邮件地址格式异常,信息错误。
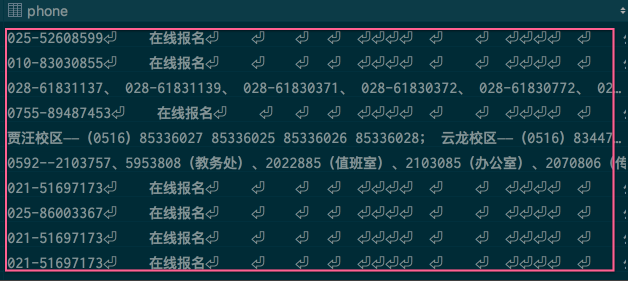
电话号码中包含了大量的回车、换行符。
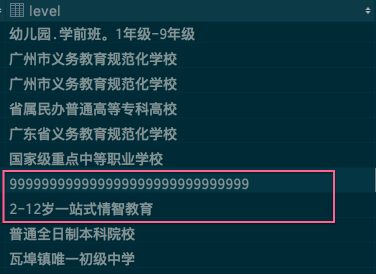
学校等级信息错误。
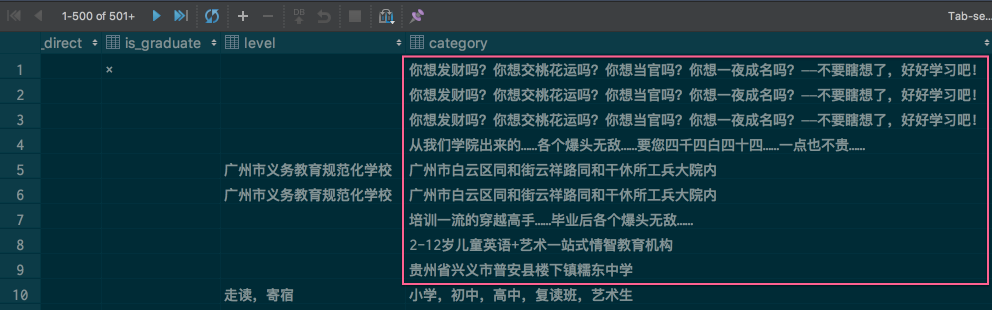
学校分类中包含广告信息。
数据修复
对于以上这些错误,可以使用下面的办法进行修复:
包含空格、换行、回车符
这类问题比较容易修复,由于数据在网页中显示的格式没有去掉,导致包含了大量的空格、换行符、回车符。使用 Python 的 replace 方法将这些字符替换掉就好了。
电话号码、网址、邮箱格式错误
对于这些规则性比较强的文本,可以用正则表达式很容易就能找出错误的信息。根据情况进行修复。
邮编缺失
网站中的学校地址信息大部分都是完整的,但是很多都缺少邮编,而根据地址可以反推出邮编,所以可以利用一些公开的 API 去补全部分缺失的邮编信息。
大部分查询邮编的 API 都是收费的,免费的额度少的可怜,根本不够用。比如聚合数据,免费的只有 100 条/天,就算是高级会员还有 5000 次/天 的限制,比较坑爹。经过搜索,找到了一个 百度邮编查询,没有次数限制,数据来源于 国家邮政局名址信息中心 ,比较靠谱。
所以接下来,对数据库中没有邮编的学校,将他们的地址和邮编查询页的地址拼接,去查询邮编,之后再用 BeautifulSoup 解析出邮编数据。就可以实现部分邮编修复了。需要注意一点,百度的 urlencode 使用 gbk 编码的。
试下来,大约修复了 2000 条缺失的邮编数据。